

Aspen: the Markup language for creating graph data (Neo4j)
As I was looking for new projects built using the Neo4j graph database, and especially the interesting use cases, I came across this markup language called Aspen, read more about it on the Neo4j community and told myself : “WOW, this is a fascinating work that deserves to be shared and celebrated !”.
In this article, we will discover together this project built by Quadri Sheriff and Matt ( I’m not sure about their real names but those are on Github :p ) using Ruby.
Sections:
- What is Aspen?
- Run some examples
- Limitations
#1# What is Aspen?

Aspen was made in 2020 and it’s a simple and friendly markup language that translates what you write on your text editor, to a Cypher query, by running a single command line.
What I liked the most about Aspen is the easy to remember syntax.
If you are new to Cypher and don’t have time to learn it, Aspen may be your awesome tool (and you have a simple data model).
#2# Run some examples

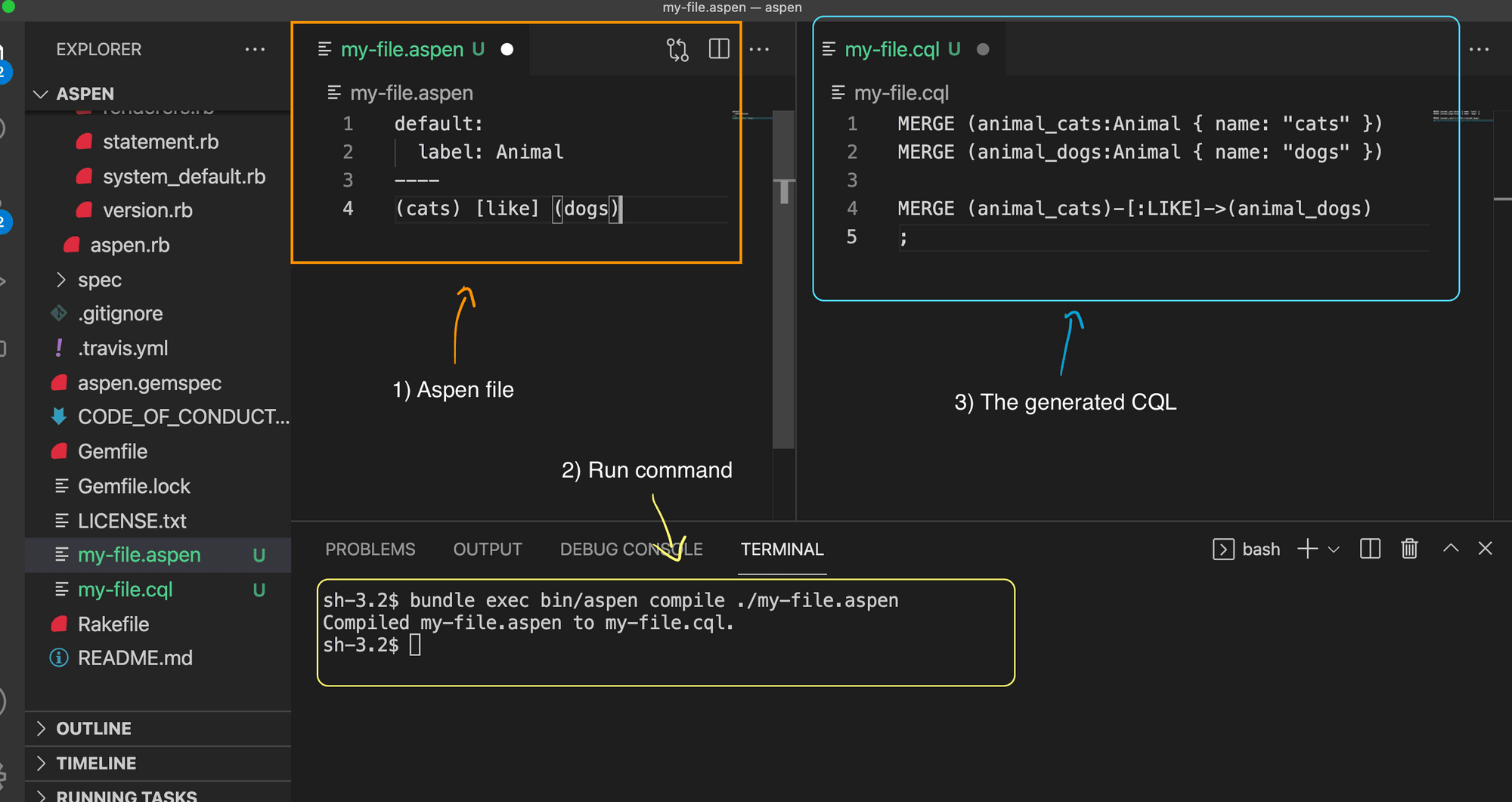
# Example 1
If we want to model a relationship between cats and dogs saying :
cats like dogs ;
In Aspen would be:
default:
label: Animal
-----
(cats) [like] (dogs)
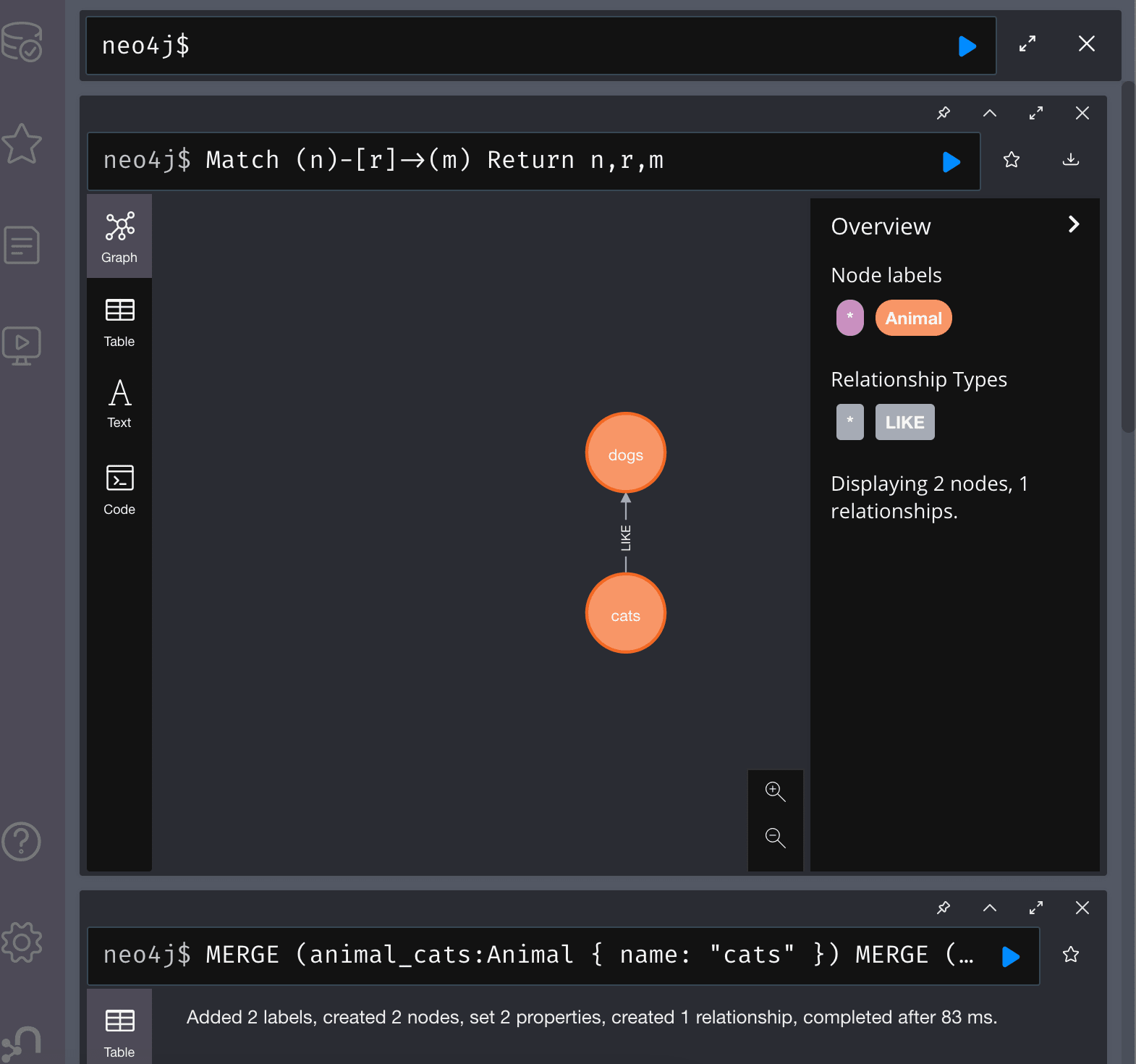
In the Neo4j browser (graph view) :
# Example 2
If we want to model a relationship between cats and dogs saying :
cats like dogs and also dogs do like cats
We are discussing here a reciprocal (undirected) relationship, and this is a quite different syntax, to let Aspen know about it:
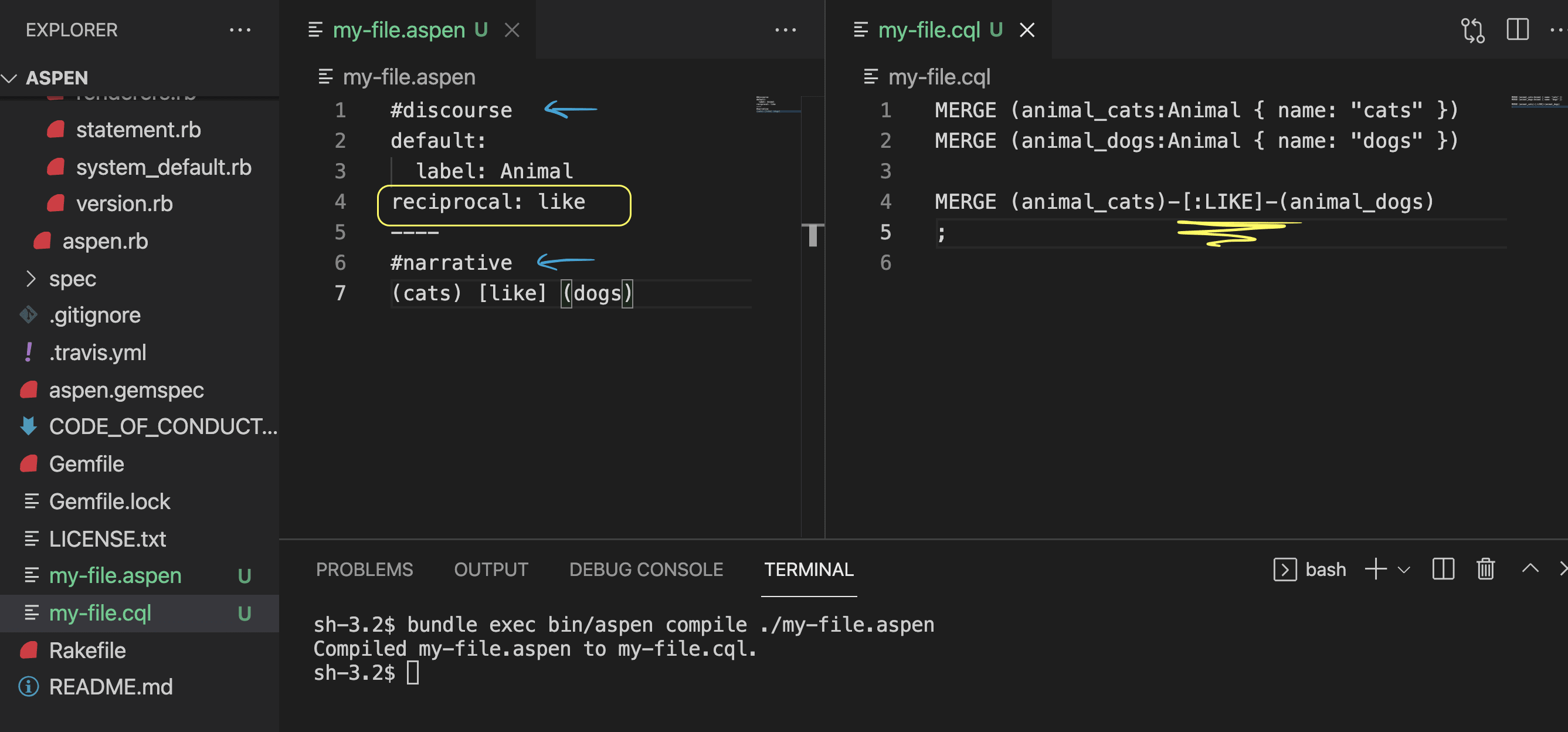
In an Aspen file, we have the discourse written at the top, and the narrative written at the bottom, always split by a line of just four dashes: ----
*Discourse:
By default, if you don’t put any name inside the label, Aspen will name it Entity and assume the text inside the parentheses is the name of that entity. Aspen can't automatically know that (dogs) and (cats) are Animal nodes, so we have to tell it using the discourse, following a YAML structure.
* Narrative:
This is the section where we write our description and observations in a narrative way with the use of () for names and [] for relationships.
Here is a minimal version for the same example:
reciprocal: like
----
(cats) [like] (dogs)
Output:
MERGE (entity_cats:Entity { name: "cats" })
MERGE (entity_dogs:Entity { name: "dogs" })
MERGE (entity_cats)-[:LIKE]-(entity_dogs)
;
# Example 3
Now let’s take a complex example (not that complex but fine):
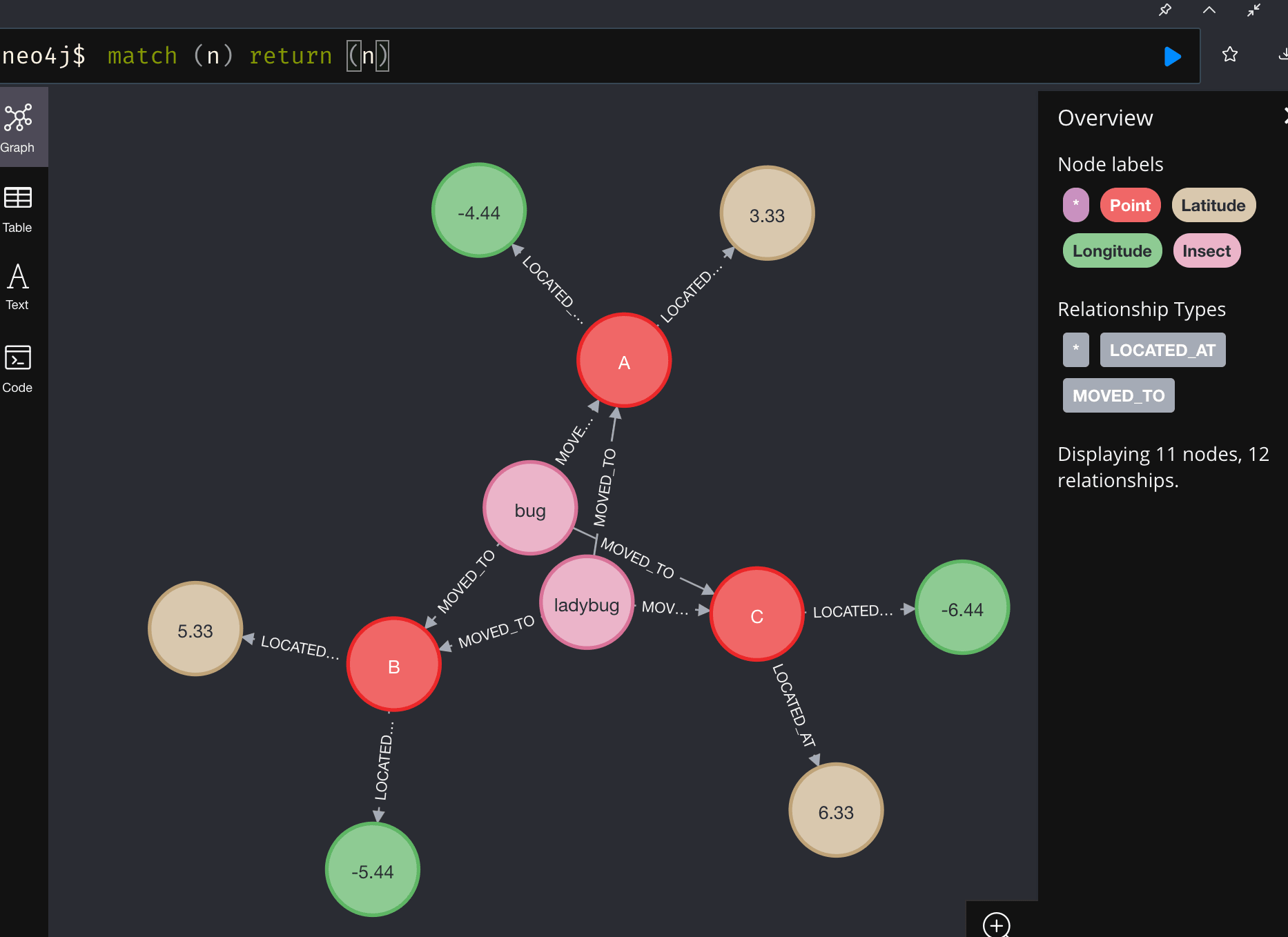
*We have three points A, B and C, each point has its own latitude and longitude.
*We have two insects ( bug and ladybug ) moving from A to C passing by B.
I did it this way (you can find your own):
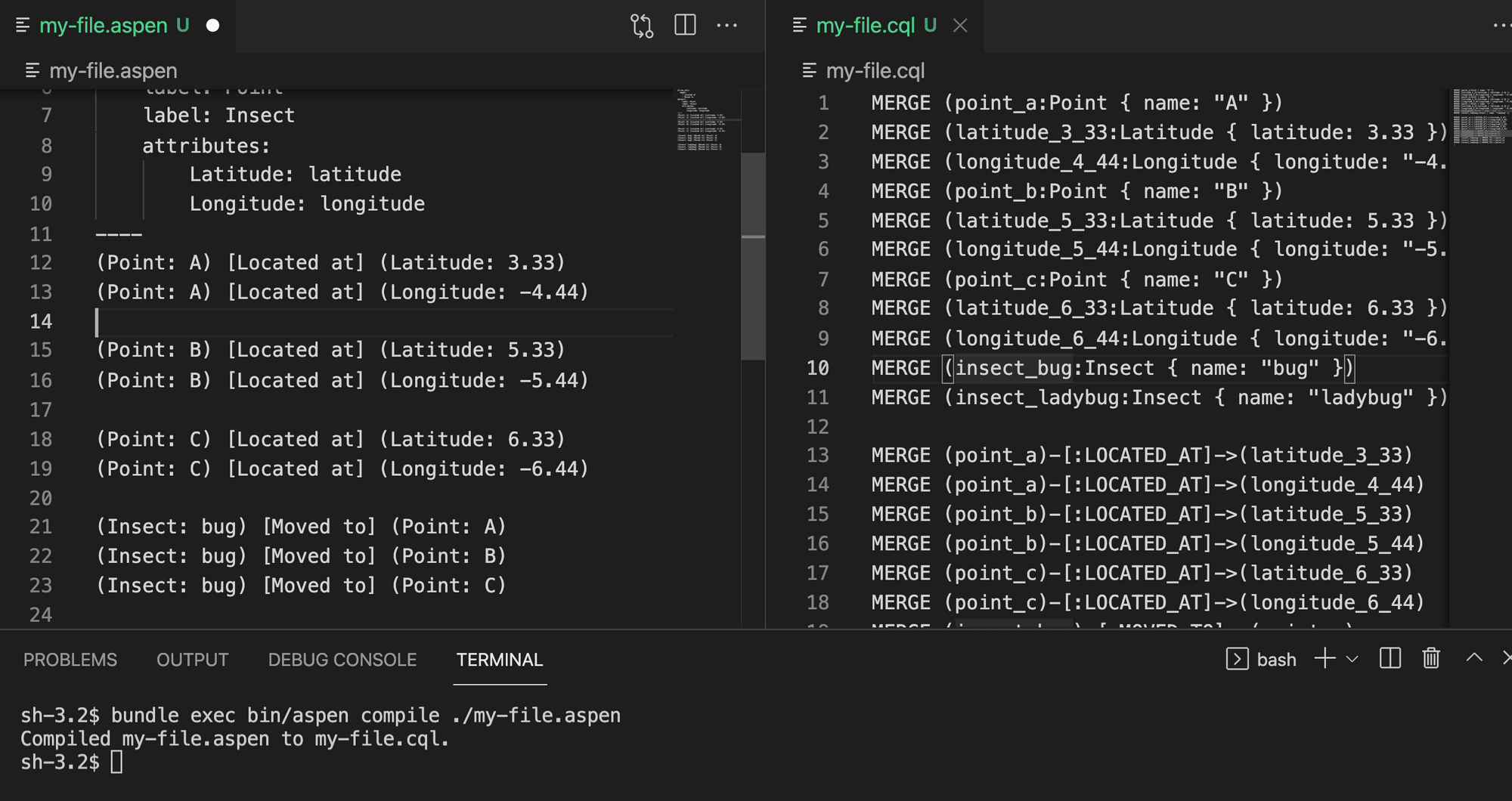
Aspen file:
allow_only:
edges:
- Located at
- Moved to
default:
label: Point
label: Insect
attributes:
Latitude: latitude
Longitude: longitude
----
(Point: A) [Located at] (Latitude: 3.33)
(Point: A) [Located at] (Longitude: -4.44)
(Point: B) [Located at] (Latitude: 5.33)
(Point: B) [Located at] (Longitude: -5.44)
(Point: C) [Located at] (Latitude: 6.33)
(Point: C) [Located at] (Longitude: -6.44)
(Insect: bug) [Moved to] (Point: A)
(Insect: bug) [Moved to] (Point: B)
(Insect: bug) [Moved to] (Point: C)
(Insect: ladybug) [Moved to] (Point: A)
(Insect: ladybug) [Moved to] (Point: B)
(Insect: ladybug) [Moved to] (Point: C)
Cypher output:
MERGE (point_a:Point { name: "A" })
MERGE (latitude_3_33:Latitude { latitude: 3.33 })
MERGE (longitude_4_44:Longitude { longitude: "-4.44" })
MERGE (point_b:Point { name: "B" })
MERGE (latitude_5_33:Latitude { latitude: 5.33 })
MERGE (longitude_5_44:Longitude { longitude: "-5.44" })
MERGE (point_c:Point { name: "C" })
MERGE (latitude_6_33:Latitude { latitude: 6.33 })
MERGE (longitude_6_44:Longitude { longitude: "-6.44" })
MERGE (insect_bug:Insect { name: "bug" })
MERGE (insect_ladybug:Insect { name: "ladybug" })
MERGE (point_a)-[:LOCATED_AT]->(latitude_3_33)
MERGE (point_a)-[:LOCATED_AT]->(longitude_4_44)
MERGE (point_b)-[:LOCATED_AT]->(latitude_5_33)
MERGE (point_b)-[:LOCATED_AT]->(longitude_5_44)
MERGE (point_c)-[:LOCATED_AT]->(latitude_6_33)
MERGE (point_c)-[:LOCATED_AT]->(longitude_6_44)
MERGE (insect_bug)-[:MOVED_TO]->(point_a)
MERGE (insect_bug)-[:MOVED_TO]->(point_b)
MERGE (insect_bug)-[:MOVED_TO]->(point_c)
MERGE (insect_ladybug)-[:MOVED_TO]->(point_a)
MERGE (insect_ladybug)-[:MOVED_TO]->(point_b)
MERGE (insect_ladybug)-[:MOVED_TO]->(point_c)
;
Back to the Aspen syntax used in this example:
- The allow_only provides protections that catch typos in node labels and edge names
- In the example we have two types of nodes : Insect and Point, how could be the best way to let Aspen know about it? Here comes (Point: C) and (Insect: ladybug) to distinguish between both types
- Aspen automatically translate Moved to into MOVED_TO in cypher
In the Neo4j browser (graph view) :
#3# Limitations
Every software has its limitations and Aspen also does. I have tested many cases but unfortunately, the more complex your use case is, the more text you should write, and many use cases don’t seem to be covered yet.
Given that underscores are not allowed, and node’s name is not customizable, also as you mentioned in the last example, I couldn't put many labels in one statement.
I think these problems are due to the lack of sponsor and contribution to this project as it’s new and only two developers are involved in its roadmap.
Conclusion:
To sum up, Aspen is interesting and its contributors are looking to improve it by adding schema and attribute protections, building a connector to communicate directly with a development/test/production Neo4j instance to publish data, also developing a UI so you don’t have to run code locally or walk through your directory looking for the generated file.
Resources:
 GitHub
GitHub
 Neo4j Graph Database Platform
Neo4j Graph Database Platform