

Design patterns for MongoDB
The key challenge in data modeling is balancing the needs of the application, the performance characteristics of the database engine, and the data retrieval patterns. When designing data models, always consider the application usage of the data (i.e. queries, updates, and processing of the data) as well as the inherent structure of the data itself.
A design pattern in general is an abstract, reusable solution to a commonly occurring problem within a given context or use case. As a mongoDB modeler you should know those modeling concepts and make use of them , each design for a specific use case .
In this article I will introduce the common problems handled by each pattern , then - inside each concept - explore examples and use cases to show the benefits behind each modeling solution.
Sections :
- Attribute pattern
- Extended reference pattern
- Subset pattern
- Computed pattern
#1# Attribute pattern :
#Problem :
Imagine you have many products, where each one has its own specifications , given the following two products :
product1 :
{
"_id": ObjectId("5c5348f5be09bedd4f196f18"),
"title": "",
"date_acquisition": ISODate("2021-12-25T00:00:00.000Z"),
"description": "",
“brand” : “”,
color :””,
size:””,
“container”:””,
“sweetener”:””
}
product2 :
{
"_id": ObjectId("5c5348f5be09bedd4f196f18"),
"title": "",
"date_acquisition": ISODate("2021-12-25T00:00:00.000Z"),
"description": "",
“brand” : “”,
capacity:””,
“input”:””,
“output”:””
}
On the application , we want to have all products where :
- the capacity is lower than 3000 and the output equals to 5V
- or the color is red
- or the size is “100 x 70 x 50”
To make it faster , we should create an index on the color , size , capacity , and output ; more fields, more indexes, in this way a repetitive task may lead to a mess when scaling the database .
#Solution :
For this reason , the “attribute pattern” suggests grouping those fields in a single array of key-value pairs .
As an example Let’s apply this pattern on the product2 :
product2 :
{
"_id": ObjectId("5c5348f5be09bedd4f196f18"),
"title": "",
"date_acquisition": ISODate("2021-12-25T00:00:00.000Z"),
"description": "",
“brand” : “”,
“specs” : [
{ “k” : “capacity” , “v”: “1000” },
{ “k” : “output” , “v”: “5V”},
{ “k” : “input” , “v” : “...” }
]
}
For now , the only indexes to create are on “specs.k” and “specs.v” .
#Common use cases :
- The Attribute Pattern is well suited for schemas with sets of fields having the same value type, such as lists of dates.
- It also works well when it comes to the characteristics of products (the above example). Some products, such as clothing, may have sizes that are expressed in small, medium, or large. Other products in the same collection may be expressed in volume etc..
#Conclusion :
The Attribute Pattern provides easier indexing and targeting many similar fields per document .
#2# Extended reference pattern :
#Problem :
Do you have nightmares about long and complex SQL queries performing too many joins ?
Even if you migrated from a 10 tables relational model in the tabular database to a 3 collections model in MongoDB, you might still find yourself doing a lot of queries that need to join data from different collections.
For sure, your MongoDB queries are nowhere going to be as complicated as in SQL.
In the world of big data anything you do too often can become a liability for your performance.
#Solution :
Now , time to introduce no physical joins pattern .
The idea behind this pattern is to embed a One-to-Many relationship on the one side or the Many-to-One on the many side .
To decide which collection should be inside the other you should consider the focus of your application when querying your database , if the focus is on the Many side , you must bring the one side to the Many .
Hint : you can extend only the part you need to join often .
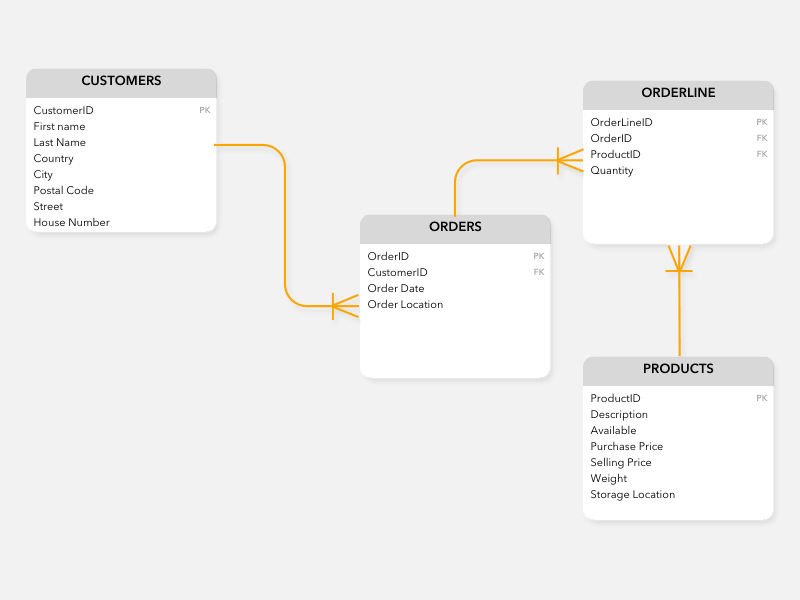
Well , let’s take an example of an e-commerce application where we need to join the customers and their orders to get the shipping address .
Applying the extended reference pattern , we have to duplicate the following attributes inside the orders collection :
- country
- city
- postal code
- street
- House number
As a result, orders collection now will have an Order_location object with above fields :
#Common use cases :
- The extended reference pattern is used on real time applications where a single physical join matters .
- Used also on analytic and catalog applications .
#Conclusion :
Deciding to minimize joins and lookups on your application increases its performance especially when duplicated fields are not mutable .
Hint : if duplicated fields mutate you should handle updates and this pattern may not be the best fit .
#3# Subset pattern :
#Problem :
MongoDB tries to optimize the use of RAM by pulling in memory only the needed documents from the disk through the RAM.
When there is no more memory available, it evicts pages that contain the document it doesn't need anymore to make room for more needed documents to process at the moment.
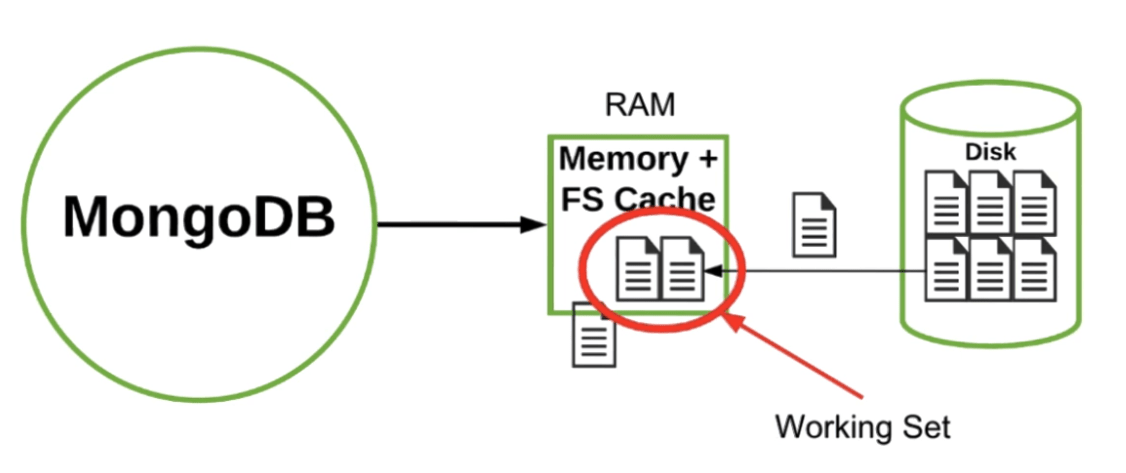
This mechanism allows a hardware configuration that does less RAM than the total size of the data on disk.
As long as the size of your working set fits in RAM, you get good performance.
The working set refers to the amount of space taken by the documents and the portions of indexes that are frequently accessed.
Either if you get into a situation where the working set is larger than RAM, documents that are needed all the time, may not fit in memory , so the server finds itself often dropping documents and fetching back from disk .
This process of constantly ejecting documents that should stay in memory is bad , pretty bad.
#Solution :
To handle this problem you must either add more RAM , scale with sharding or reduce the size of your working set .
The last solution can be achieved by considering the subset pattern which focuses on splitting a collection in 2 collections : most and least used part of the document .
We can reduce the size of the working set while processing joins on the Many-to-Many or one-to-Many relationships by duplicating the often used attributes on the most used side (extended reference pattern)
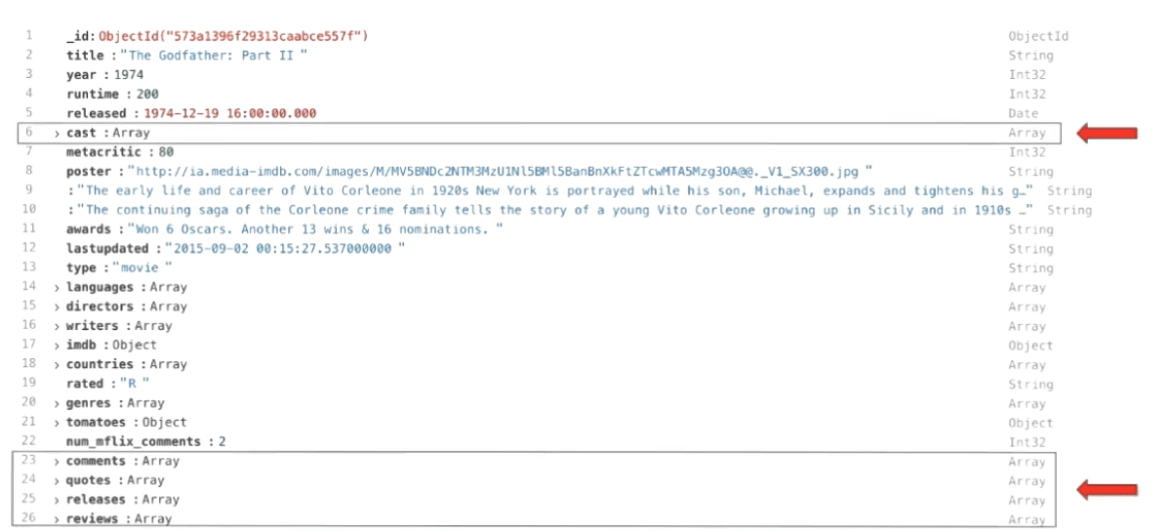
A simple example can be the following document from a movies collection :

Most of the time users want to see the top actors and the top reviews, rather than all of them. The ideal solution is to keep only the most used fields and move others to a separate collection :
#Common use cases :
- List of reviews or comments on an article .
- List of actors in a movie .
#Conclusion :
As a result of applying the subset pattern, our working set will retrieve additional documents faster since they will be smaller , but the fact that you break documents in two and duplicate some info means that the database will require a little bit more space on disk.
However, this is not a big issue as this space is much cheaper than RAM.
#4# Computed pattern :
#Problem :
You may find yourself redoing the same mathematical , roll-up or fan-out operations which are all a kind of computations/transformations, if repeated can lead to a very poor performance.
On big data systems, doing the same computation over and over is very expensive and ends up using a lot of CPU .
#Solution :
The solution is to perform the computation and store the result in the appropriate document and collection. If you need to redo the computations or want to be able to redo them, just keep their sources .
As an example , we want to calculate the total of payments done on our store from the very beginning , if you think the $sum aggregation is enough for you , then you should consider this pattern to avoid computations each time a new payment is processed .
To handle this , we will add a new computation collection (for example : total_amount_payments ), once we have a new payment we should update the sum inside .
In this case the write operation is better than reading all documents over and over .
#Common use cases :
- Frequent aggregation framework queries .
- IOT ( Internet Of Things ).
- Event sourcing .
#Conclusion :
The computed pattern allows for a reduction in CPU workload when the data needs to be repeatedly computed by the application .
If you make it till the end , I hope you liked this introduction to the world of design patterns for MongoDB .
Still want to explore more ?
Here are some useful resources [ linked below :) ]
Resources :

